

Why do we have programming languages in the first place? Part 1

There are hundreds of computer programming languages. But why? Why do we keep inventing them?
In this two-part mini-series, I will share my understanding and thoughts on programming languages and computers in general. This first part will cover:
- Types of processors
- The language bridging us and processors
- Key terms such as instruction set, instruction set architecture (ISA), machine code, assembly language
We have at least 500 programming languages in existence today. 1 But why do we continue to invent them? Let’s talk! But first:
Why do computers exist in the first place? 💻
Computers are expensive and require extensive engineering effort to develop. As individuals, we invest hundreds of dollars 💲 each year in our personal computers, including laptops, gaming consoles, mobile phones, desktops, and more. But why? They must serve a purpose, correct? Indeed. Actually, each of these computers addresses a specific problem we encounter. Computers can perform complex mathematical computations, facilitate aircraft landings, entertain us, enable over-the-air communication, and even contribute to the discovery of planets in space! But how do they accomplish these tasks? What is the magic behind their functionality?

ENIAC, Electronic Numerical Integrator and Computer, designed in 1945 to solve military-related problems, stands as one of the earliest computers (The whole thing in the room is a single computer. Power consumption was higher than 150 kW). With a cost exceeding 6 million US Dollars (adjusted for inflation), it was capable of performing only 5000 operations per second—a figure that may seem modest compared to today’s standards but still exceeded human capacity at the time. Photo
{kind=link}
The magic lies in the ability to leverage information to accomplish these tasks. Computers possess memory to store information and fast communication links to facilitate the exchange of data. Ultimately, the crux of computer functionality revolves around the generation and processing of information.
Computers are incredible inventions created by smart people, but there’s no actual magic involved. They work because they’ve been carefully designed and engineered. If you want to experience something truly magical, consider exploring the wonders of nature through the study of natural sciences. 🪄
Nearly all problems solved by computers boil down to mathematical problems. Computers excel with numbers, capable of executing algorithms on data orders of magnitude faster than a human could. But how do they achieve this?
Processors
Processors serve as the heart ❤️ of computers (or brains 🧠, whatever organ you choose). A processor is an electronic hardware component capable of manipulating numbers at an incredibly high speed. While processors themselves can’t store data, they “process” (hence their name) the stored data, such as in RAM, and generate new data. They can achieve this at rates of billions of operations per second. Examples of processors include the CPU (Central Processing Unit), GPU (Graphics Processing Unit), and TPU (Tensor Processing Unit).
CPUs, or Central Processing Units, are general-purpose processors found in nearly all computers and many electronic devices. They are designed to handle a wide range of tasks, such as text editing, web surfing, and number crunching, typical of personal computers. Unlike specialized processors optimized for specific tasks, CPUs are not tailored to excel in any single function but rather are engineered to efficiently handle a variety of tasks.

The MOS Technology 6502 is a highly renowned microprocessor introduced in 1975, widely utilized in numerous microcomputers and video game consoles during the 1980s era. Capable of executing 1-2 million operations per second, it represented a significant leap in computing power compared to the 5000 operations per second capability of the ENIAC, which was designed in 1945. Despite its enhanced performance, the price of the 6502 remains relatively affordable, around $150 today when adjusted for inflation (originally $25 in 1975). Photo
{kind=link}
GPUs, or Graphics Processing Units, differ from CPUs. While they are also processors, their internal architecture is specifically optimized to efficiently handle calculations required for graphical tasks. GPUs excel in processing graphical data by leveraging parallel computing, utilizing thousands of multiple processors designed to execute tasks simultaneously. Because neural network problems share a similar parallel nature to graphics tasks, GPUs are increasingly being utilized not only for graphical applications but also for solving AI problems. Nonetheless, they remain processors at their core.

The modern GPU card, Nvidia’s RTX 4090, released in 2022 for approximately $1600, boasts impressive capabilities. With its GeForce 40 series GPU, it can perform 73,000 billion single-precision floating-point operations per second while operating under 450W. Photo
{kind=link}
TPUs, or Tensor Processing Units, are custom processors specifically designed for neural network applications. Developed by Google, TPUs are engineered to perform the mathematical operations necessary for neural network tasks more efficiently than GPUs. Unlike GPUs, TPUs are tailored solely for optimizing the performance of neural network computations.

Photo of TPUv3 processors. We can’t see them directly because they are under heatsinks. TPUv4 announced in 2021 is capable of doing 275,000 billion operations per second while operating under 170W. Photo
{kind=link}
Microcontrollers, MCUs, present in nearly all electronic devices, also contain processors within them. In general, these processors are specifically designed to handle tasks that are not computationally intensive. However, certain microcontrollers are engineered to execute tasks with minimal power consumption, enabling devices to operate for years a single battery.

A PIC microcontroller from Microchip Technology. Photo
{kind=link}
As evident, there exist numerous types of processors, beyond the examples provided, each tailored for specific purposes. Various companies are involved in the design and manufacturing of these processors. For instance, Intel and AMD are renowned for their CPUs, while Nvidia specializes in GPUs.
However, regardless of the type or manufacturer, all these processors fundamentally operate in a similar manner. The process of utilizing or programming them has remained essentially the same for decades, spanning across a wide range of processors.
Talking with Processors
Now that we’ve grasped the importance of the processor in a computer system,
whether it’s a CPU, GPU, TPU, or any other variant, let’s delve into its primary
functions. Broadly speaking, a processor performs two types of tasks:
arithmetic operations, which involve mathematical computations like
addition, multiplication, and division, and logical operations, which entail
making decisions based on conditions—for instance, determining if number A is
greater than B and taking appropriate actions accordingly. But how exactly do
we communicate with a processor to get our tasks done?
Let’s imagine that I’ve purchased an AMD Ryzen 7 8700G CPU from a computer store. This CPU, designed by AMD and released in early 2024, is capable of performing billions of operations per second, which is quite impressive. Now, let’s say I simply want to add two numbers together and obtain the result. How can I communicate this task to the CPU? How do I tell the CPU, “Hey, here are two numbers. Please add them together and return the result to me?”

AMD Ryzen 7 8700G. Photo by Tom’s Hardware.
As we’ve observed, there is a wide array of processors available today, each tailored to different applications with various optimizations such as power consumption and speed. Over the past 80 years, these processors have undergone dramatic changes in size, performance, and price. Comparing the computational power of a modern basic cell phone to that of the Apollo Guidance Computer, for example, would be practically meaningless. However, with all these historical advancements and variations, one fundamental aspect remains nearly unchanged: the basic operational principle of a processor.
Processors are essentially devices designed to execute tasks, functioning as an execution engine of sorts. Regardless of their processing power, a processor simply carries out the instructions it is given—no more, no less. We provide a list of commands, or instructions, to a processor, and it executes them one by one. Each instruction tells the processor precisely what action to take. A computer program essentially consists of an ordered set of instructions for the processor to follow. These instructions are stored in memory, typically RAM, and can be accessed by the processor. The processor then begins executing these instructions sequentially, from start to finish. Below is an illustration of how a program appears in memory:
Instruction 001: Do this
Instruction 002: Do that
Instruction 003: If A < N, do this otherwise do that
...
Instruction 875: Do this
Instruction 876: End
As you may have noticed, for a processor to be capable of performing useful tasks, it needs to support more than just one instruction. A processor that can only add two numbers together without any additional functionality wouldn’t be very practical, would it? Therefore, processors are designed to support a wide range of instructions, and the set of instructions supported by a processor is called its Instruction Set.
If you’re interested in this topic, you may have come across two terms: RISC
and CISC. In these terms, IS in the middle stands for Instruction
Set. RISC stands for Reduced Instruction Set Computer, while
CISC stands for Complex Instruction Set Computer. Anyway, let’s
proceed with our exploration: talking with processors.
Let’s delve into instructions in more detail. As mentioned earlier, instructions are stored in memory and are accessible by the processor. Computers operate using numbers, binary numbers most of the time, which consist of 0s and 1s. This applies to both memory and processors. Each instruction communicates to the processor what action to take. To efficiently store these commands in memory, each command is encoded with a number. For instance, for a specific processor, reading a “01” from memory might indicate an addition operation, “10” for subtraction, “11” for comparison, and so on. In a moment, I’ll provide a real-life example from a processor to illustrate this further. Stay tuned!
Example: PIC16F84
Let’s examine a real-life example. To maintain simplicity and focus on the topic without getting distracted by advanced features implemented by a processor, I’ve chosen an old microcontroller from Microchip Technology: the PIC16F84. This microcontroller holds a special significance for me because it was the first microcontroller I programmed when I began experimenting with hobby electronics in high school.

PIC16C84 is an older version of PIC16F84. It was introduced in 1993. Photo
{kind=link}
The datasheet of the PIC16F84 microcontroller is available on the manufacturer’s website. Let’s navigate to the “Instruction Set Summary” section, located on page 55, to gain insight into the instructions supported by this microcontroller.
This microcontroller consists of a CPU and an internal memory to store instructions that will be executed sequentially by the CPU. However, the memory structure is somewhat unusual because each row has a width of 14 bits. Typically, we are familiar with memories with widths that are multiples of 8 bits, such as 8, 16, or 32 bits. Nevertheless, there’s nothing inherently wrong with having a memory width of 14 bits. We can visualize the memory as follows:
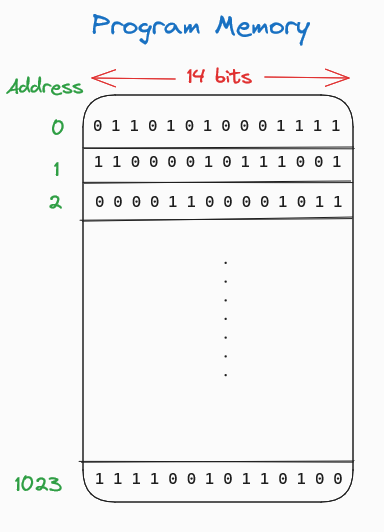
Note that each row is filled with random 14-bit data just for illustrative purposes.
The internal program memory of the PIC16F84 is capable of holding 1024 instructions, each with a width of 14 bits.
On the same page, page 55, the instruction format is illustrated as follows:

PIC16F84 Instruction Format
The first notable aspect is that this particular processor can interpret four different instruction formats. Depending on the instruction category, each bit in the 14-bit word carries a distinct significance. Every instruction includes a common field known as OPCODE. All instructions supported by the processor are assigned a unique number, referred to as the OPCODE. The remaining bits may be interpreted differently by the processor based on the instruction, i.e., the OPCODE.
On the next page in the datasheet, Table 9-2 lists all instructions, i.e., the Instruction Set, along with their corresponding OPCODEs.
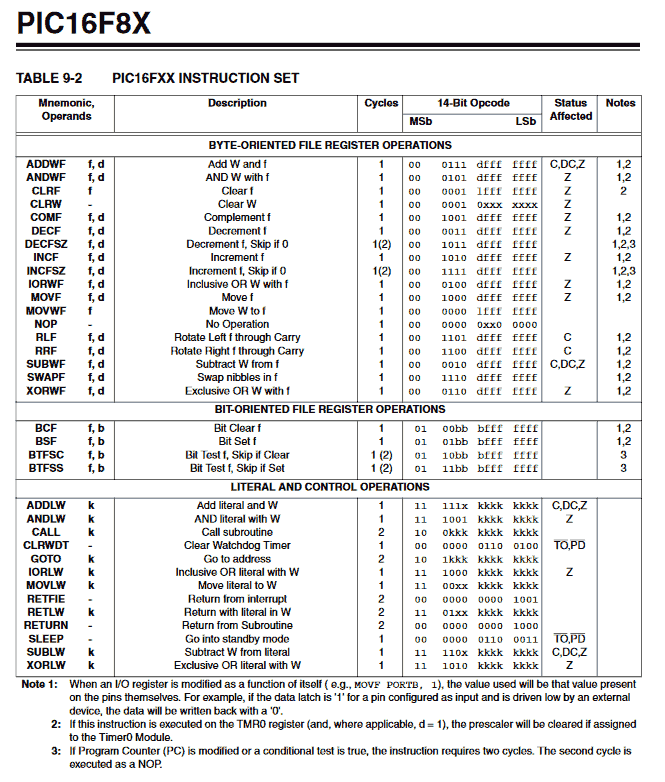
All instructions supported by PIC16F84
The PIC16F84 supports 35 distinct instructions. For humans, it is not practical to memorize the bit patterns for all instructions. Therefore, each instruction is assigned a nickname called a mnemonic. In this context, a mnemonic is the term for the instruction name.
Some instructions, like SLEEP, don’t require any additional information from
the programmer. However, many instructions do need additional information to
operate. For instance, CLRF is used to fill a memory location with all 0s.
However, we have to provide the address of the location, otherwise CLRF won’t
know which memory location to clear. These additional parameters given with
instruction names are called operands in this context.
To delve deeper into the subject, let’s analyze an instruction thoroughly. Let’s
consider the ANDLW instruction. The detailed explanation is provided on page 57
of the datasheet as follows:

The first 6-bit value, 111001, represents the OPCODE of this instruction. The
remaining 8 bits constitute the single operand required for the instruction.
Essentially, the ANDLW instruction performs a logical AND operation between
the content of the W register and the constant value encoded in the 8-bit
operand field. The result is then stored back into the W register.
ℹ Note that the W register is a special storage area found in the processor of
this microcontroller. This name is specific to this processor, and other
processors may have a different number of registers with different names.
Therefore, don’t worry too much about this naming convention—it’s unique to this
particular microcontroller.
The processor in the microcontroller essentially reads 14-bit wide instructions
from the program memory, row by row. Let’s say the processor reads the value
11100100010010. When we split this value, we have 111001 concatenated with
00010010. This represents the ANDLW instruction with an operand value of
0x12 (in hexadecimal, 18 in decimal). When the processor reads this particular
14-bit value, it performs a logical AND operation between the value stored in
the W register and 0x12, and then writes the result back to the W register.
The program memory could be like this:
<14-bit wide instruction>
<14-bit wide instruction>
...
11100100010010 -> ANDLW 0x12
...
<14-bit wide instruction>
If you continue reading the remaining part of the datasheet, you’ll notice that each instruction is explained in detail. Similarly, all processors have similar documents that explain each instruction and its effects on the state of the processor (such as registers).
The set of instructions + the architecture that behaves according to those instructions is referred to as the Instruction Set Architecture (ISA).
In summary, processors only understand instructions, often accompanied by operands. To achieve meaningful outcomes, programmers must provide instructions in a logical order. Processors lack awareness of the tasks they are performing (such as calculating the Fibonacci Sequence); it is the programmer’s responsibility to ensure that the set of instructions executed by the processor yields a meaningful result. This result may be stored in main memory, such as RAM. Importantly, processors do not understand programming languages like JavaScript, Python, or C. They can only execute instructions stored in memory, supported by their own ISA, one by one, without deviation.
ISA: The Contract
Commonly, ISA is defined as the contract between software and hardware. Considering ISA as an agreement between hardware and software people is a very apt representation. Let’s explore why.
In the previous example, we explored the ISA implemented by Microchip company in the PIC16F84 microcontroller. However, we didn’t delve into the internals of the processor. We don’t know how Microchip uses flip-flops and transistors to build the processor. We don’t know how the logical AND operation is implemented at the transistor level, and we don’t need to! The only thing we need to utilize a processor designed by a company is the details explained in the ISA.
The concept of ISA is similar to API (Application Programming Interface) in the software world. As programmers who are willing to utilize existing processors, rather than design them, we only need to know how to use them, not their internal structure. As long as processor manufacturers adhere to the rules defined in the corresponding ISA, they are free to design whatever circuit they like, and programmers won’t notice any difference.

ISA is the contract between software and hardware. Taken from Onur Mutlu’s lecture slides.
Processor design companies, also known as hardware companies, have the flexibility to design processors with vastly different internal architectures while still supporting exactly the same ISA. These differences in internal structures can result in the design of processors that are more power-efficient, faster, or cheaper.
The contrast between two processors supporting the same ISA can be significant. One processor may be widely adopted and used in numerous systems, while the other may not be used at all, potentially leading to financial crises within a company.
In summary, the metrics of two processors can be dramatically opposite, even if they implement the same ISA.
ISA: Bad and Good News
Okay, we understand that in order to utilize a processor and write programs that perform valuable tasks, we have to study the ISA of the processor and program it accordingly. But how many ISAs are currently in use? Can we talk about a universal ISA that all processors support, so we as programmers can learn one ISA to work with all processors?
The bad news is that there is not just one ISA, I’m afraid. Since the inception of the first electronic processors, companies began developing their own ISAs. Therefore, we can’t talk about a universal ISA. However, the good news is that processors are grouped together in such a way that a group of processors implements the same ISA. So, the number of ISAs is less than the number of designed processors.
For example, as programmers, we don’t need to learn a different ISA for each CPU designed by Intel; fortunately, they share a common ISA base.
The term architecture commonly refers to the ISA implemented by a processor. From a CPU standpoint, common architectures (ISAs) include ARM (v7, v8, v9…), x86, x86-64, MIPS, RISC-V, etc. For example, there are multiple processor design companies designing ARM CPUs. From a programmer’s viewpoint, instructions suitable for the ARMv7 ISA, for instance, can be executed on CPUs from both companies.
Today, many architectures (ISAs) have “plugin” capabilities. While maintaining the base instructions as a minimum requirement, a vendor may implement additional instructions. These additional instructions are often referred to as extensions.
For example, ARM has SVE (Scalable Vector Extension) to implement fast vector-based operations. If a program uses these kinds of extensions, these instructions won’t work on a similar processor lacking that extension.
Putting Instructions into The Memory
Until now, we’ve assumed that instructions executed by the processor are available in the memory somehow. But how do we actually put those instructions into memory?
In today’s computers, when we double-click an application, the instructions for the application are loaded into memory by the operating system (OS). We don’t even think about the process of reading instructions from disk and putting them into memory (RAM) and letting the CPU run the instructions. However, this process wasn’t as trivial in the old days as it is today.
Many old computers lacked an operating system to read instructions from storage and load them into memory. Some had operating systems available, but the cost of operating systems or computers capable of running them was prohibitively high, so people often didn’t choose those systems. Additionally, storing programs on paper (punch cards) could be cheaper than storing them on hard disks. Since this subject is beyond the scope of this post, I won’t go into details, but if you’re interested, I recommend watching the following video:
and
Altair 8800
As an example, I would like to talk about the Altair 8800. According to many resources, it is considered the first personal (micro)computer. 2 It features an Intel 8080 processor and was designed by MITS in 1974. The Altair 8800 played a significant role in the history of Microsoft and Apple.

{kind=link}
Did you notice something? This computer doesn’t have a keyboard, mouse, or screen! How are you supposed to program it? Well, you would use the front panel, which consists of a bunch of switches and LEDs, and perform something called Front Panel Programming.

{kind=link}
By toggling switches, a programmer inputs 0s and 1s into the memory, which are
then read by the processor. After inputting all instructions one by one and
hitting the RUN button, the processor executes the instructions stored in the
memory. After running all instructions, the results can be read back by toggling
switches and observing LEDs.
This is how a “real programmer” operates a computer!
and
Machine Language
As you can see, we communicate with computers via instructions given in the corresponding ISA. The instruction set resembles a dictionary for a language that a processor can understand. This language, which a processor can understand or “speak,” is called machine language. Communicating with a processor, or with a more technical term, programming it with raw instructions using 0s and 1s, is called machine language programming. Programming a computer with 0s and 1s directly is the lowest level of programming possible. Machine language is also known as machine code.
In programming terminology, we have low-level and high-level languages. Low-level languages are closer to the machine than to a human. On the other hand, high-level languages are more suitable for humans; they resemble natural human language more than machine language.
Clearly, programs written with 0s and 1s are very close to machines but not to humans. However, this is what computers or processors understand: 0s and 1s.
Assembly: The First Step Towards to Programming Languages
Although programming a computer with machine language is a natural way of programming from the perspective of a processor or computer, understanding a bunch of 0s and 1s put together isn’t an easy task for a human. A programmer needs to communicate with colleagues, review code, and so on. However, trying to understand 0s and 1s and writing programs with them is error-prone and a very time-consuming task.
So instead of writing programs in 0s and 1s, why can’t we write them in a more human-readable way and then convert them to 0s and 1s that a processor can understand? This is exactly how assembly languages work!
🤔 Trivia: It is believed that the first assembler program was developed for a British computer known as EDSAC in 1949. 3
If you remember, we defined two terms with the PIC16F84 example: mnemonic and
operand. Instead of writing raw 0s and 1s, we can write instructions using
“nicknames” of instructions like ADD, SUB, GOTO, CLRF, etc. Then, a
computer program called an assembler converts those words into 0s and 1s
that a particular CPU can understand. Programmers can interpret words like ADD
more easily than 000100101, right?
An assembler serves a broader purpose beyond simply translating words into 0s and 1s. I’ll delve deeper into this concept with an explanation using a specific assembly program designed for the PIC16F628, a well-known microcontroller from Microchip.
CNTR1 EQU H'20'
CNTR2 EQU H'21'
CLRF PORTB ; Clear PORTB
BANKSEL TRISB
CLRF TRISB
BANKSEL PORTB
LOOP
MOVLW h'00'
MOVWF PORTB
CALL DELAY
MOVLW h'FF'
MOVWF PORTB
CALL DELAY
GOTO LOOP
DELAY
MOVLW h'FF'
MOVWF CNTR1
LOOP1
MOVLW h'FF'
MOVWF CNTR2
LOOP2
DECFSZ CNTR2, F
GOTO LOOP2
DECFSZ CNTR1, F
GOTO LOOP1
RETURN
END
This code doesn’t accomplish anything particularly useful; it simply sets some registers and then loops through two nested loops. However, the intention here is to illustrate the structure of an assembly language program.
Most of the lines in the program correspond to a single instruction for the
processor, such as MOVLW, MOVWF, and CALL. Some of them are included for
the sake of simplicity in creating assembly programs.
For example, CNTR1 EQU H'20' creates a substitution word CNTR1, which will
be replaced by 0x20 when the assembler converts the program into 0s and 1s
that the processor can understand. This functionality is very similar to the
#define CNTR1 0x20 preprocessor directive in C. The same concept applies to
CNTR2, PORTB, and TRISB. This feature of the assembler simplifies
modifications to the program. Instead of writing 0x20 everywhere and then
performing a search-and-replace, one can easily change CNTR1 EQU H'20' to
another value if needed. The definitions for PORTB and TRISB are provided by
the vendor so that the user doesn’t need to memorize the actual register
addresses.
Another feature commonly supported by assemblers is the use of labels. DELAY,
LOOP, LOOP1, and LOOP2 are labels. When a label is used with an
instruction like GOTO, the assembler automatically calculates the address of
the instruction labeled by the label and generates the correct instruction that
directs the processor to start executing that instruction. This simplifies the
programmer’s life, as otherwise, the programmer would need to manually calculate
offsets between instructions.
Many assemblers offer features to fill a memory region with text, typically represented in ASCII, along with other handy functionalities. However, an assembly language for a processor strictly adheres to its ISA and machine language specifications. These additional features simply make a programmer’s life a bit easier. Since assembly language closely mirrors machine language with some helpful additions, it is also referred to as symbolic machine language or symbolic machine code. While we write programs in a manner similar to machine language but we use symbols to create them. Ultimately, the assembler converts the program into machine language, consisting solely of 0s and 1s.
Example
Since assembly languages strictly adhere to the instructions defined in a
particular ISA, we have different assembly languages for each architecture.
Let’s write a very simple function for different architectures. The function takes
two inputs and calculates the sum of their squares: x^2 + y^2.
For x86-64 architecture:
mov eax, DWORD PTR [rbp-20]
imul eax, eax
mov edx, eax
mov eax, DWORD PTR [rbp-24]
imul eax, eax
add eax, edx
mov DWORD PTR [rbp-4], eax
For RISC-V 64-bits architecture:
lw a5,-36(s0)
mulw a5,a5,a5
sext.w a4,a5
lw a5,-40(s0)
mulw a5,a5,a5
sext.w a5,a5
addw a5,a4,a5
sw a5,-20(s0)
and for MIPS:
lw $2,24($fp)
nop
mult $2,$2
mflo $3
lw $2,28($fp)
nop
mult $2,$2
mflo $2
addu $2,$3,$2
sw $2,8($fp)
As you may easily notice, the same functionality is achieved with different assembly programs for different architectures. Since their ISAs are different, the corresponding assembly programs also differ. Although all of them share a similar pattern and some instructions appear similar, one has to learn each assembly language for the processors they work on.
A similar issue persists even when working with very similar processors. Let’s consider another example. In this case, assume we have three variables, x, y, and z, and we aim to implement z = x + y, where all of them are integers with a width of 64 bits.
For ARMv7:
ldr r1, [sp, #16]
ldr r0, [sp, #20]
ldr r3, [sp, #8]
ldr r2, [sp, #12]
adds r1, r1, r3
adc r0, r0, r2
str r1, [sp]
str r0, [sp, #4]
For ARMv8:
ldr x8, [sp, #24]
ldr x9, [sp, #16]
add x8, x8, x9
str x8, [sp, #8]
The assembly programs for both architectures are very similar; they both contain
almost the same instructions. However, the program for ARMv8 has almost half the
number of instructions compared to the program for ARMv7. This is because ARMv8
is a 64-bit processor architecture, and since the “natural” word length of this
architecture is 64 bits, a single add instruction is sufficient to sum up two
64-bit variables. On the other hand, ARMv7 is a 32-bit processor architecture
and cannot handle 64-bit variables as easily as ARMv8. Therefore, one has to
split a 64-bit variable into two 32-bit variables and perform multiple
additions.
As you can see, programming in assembly language is easier than programming in machine language. However, one must learn the ISA for each architecture and consider other factors such as variable sizes and architectural details. Let’s imagine that you’ve written a fairly large assembly program for the ARMv7 architecture, and one day you need to run the same program on an x86-64 architecture. In that case, you would have to rewrite your program in x86-64 assembly language. Rewriting the same program for a different architecture or system is known as porting. At the assembly language level, porting is not an easy task because you have to rewrite the entire program again. If you are supposed to port the same program to five different architectures, good luck! You will have to rewrite and debug the same program five times using different assembly languages.
As we conclude this section, it’s important to recognize that even within the same architecture, there can be multiple assembly language variants. Take x86 assembly, for instance, where two prominent styles exist: AT&T and Intel. 4 While these styles may appear similar, they differ in the order of instruction parameters. Nevertheless, despite these variations, they ultimately produce the same machine code.
This concludes part 1. In part 2, we’ll explore what can be built on top of assembly language, and I’ll share my personal insights on the existence of various programming languages. Stay tuned for more!
-
🤓 One more?

15 Features of The C Programming Language
What kind of language is C? What are the properties? Which paradigms does it belong to? How can we categorize it?
💭 Comments
Comments are provided by giscus. You need to use and authenticate your GitHub account to post a comment. Comments are stored on the Github Discussions.
24-9